NLP 4 - 단어 임베딩
2021. 8. 1. 13:34ㆍalgorithm/Deep Learning











임베딩의 종류

1. Tf-idf



위의 방법은 문서의 개수가 제한되어 있다는 한계점
-> 단어-문서 를 단어-단어로 바꾼다

주변의 n개의 단어를 같이 본다
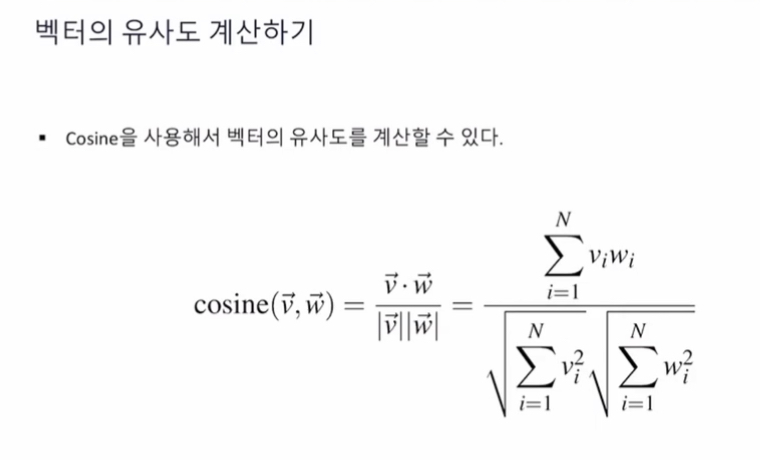
단어의 길이보다 “방향”이 중요
= 각도 theta 가 중요
두 단어의 벡터간의 각도 theta가 작을 수록 두 단어는 비슷하다



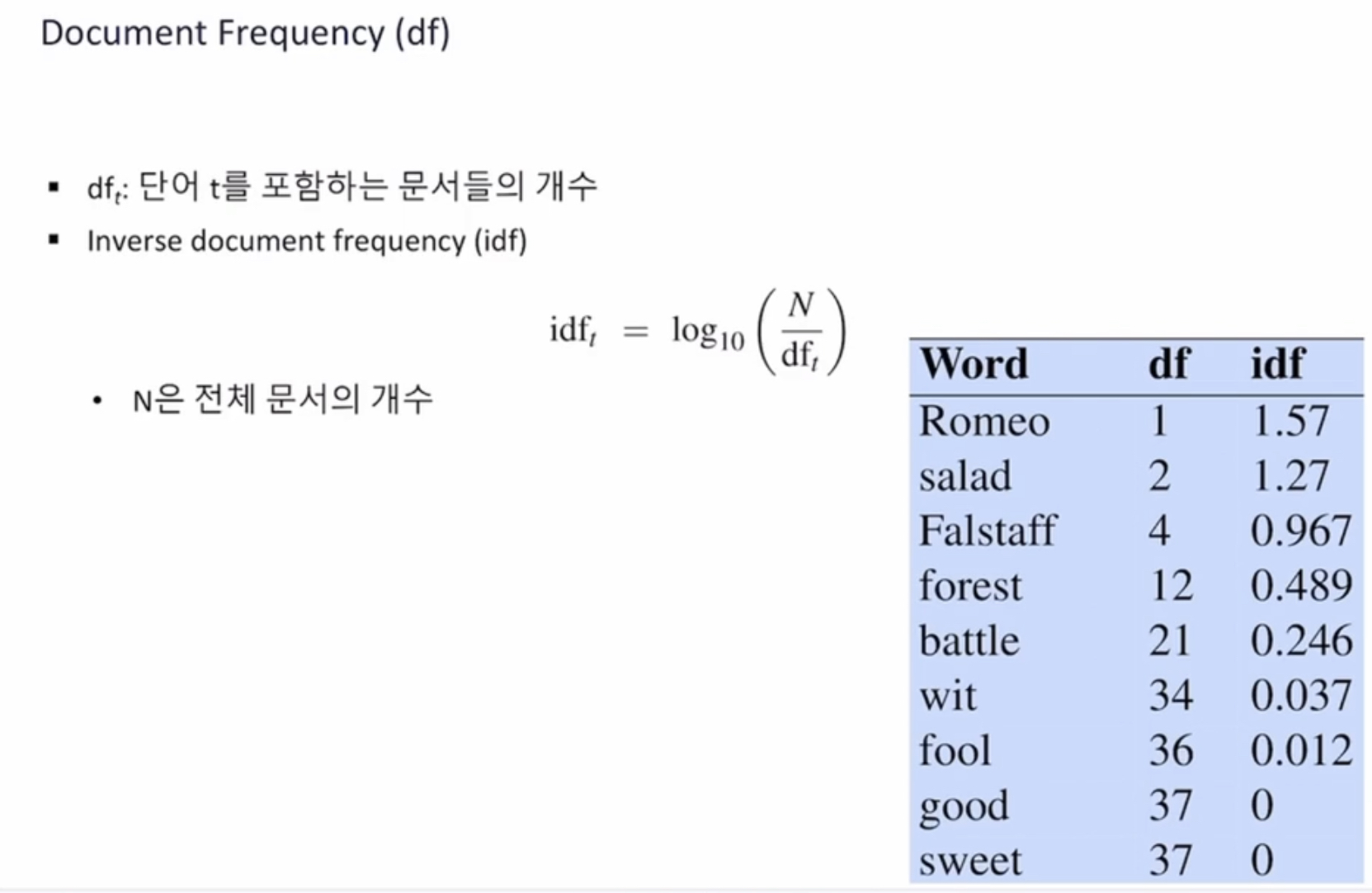
로그를 취함으로써 좀 더 smooth 하게 증가하도록 함
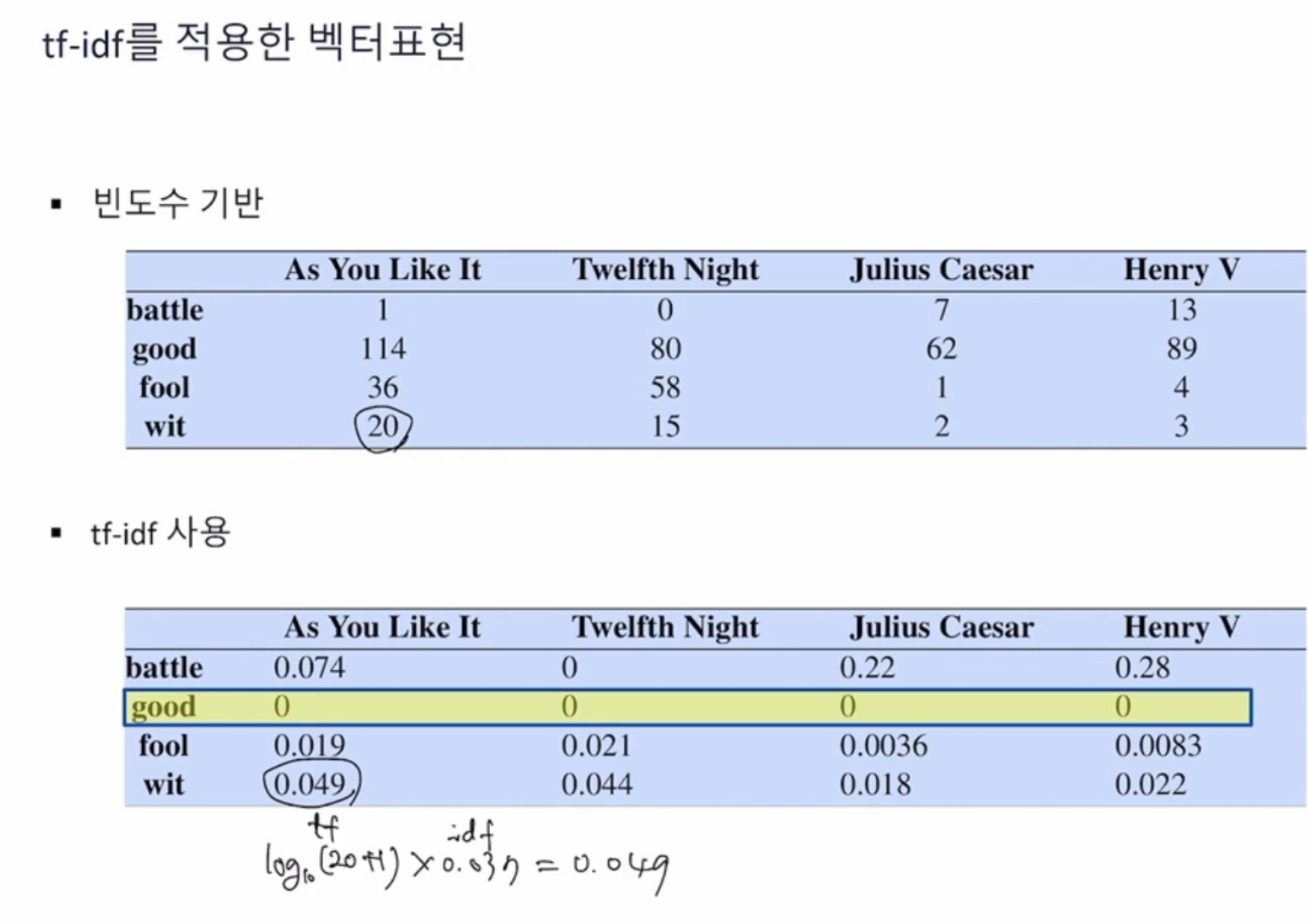


Td-idf 는 단어의 개수(= v) 만큼 연산이 커지지만
임베딩은 d 가 몇백개 수준
파이토치나 텐서플로우에서 두 가지를 동시에 사용할 것
-> wide 한 표현과 deep한(보통 임베딩은 여러 레이어를 쌓아서 씀) 표현의 특징을 결합
'algorithm > Deep Learning' 카테고리의 다른 글
| NLP 6 - NLP 와 딥모델 (0) | 2021.09.05 |
|---|---|
| NLP 5 - 단어 임베딩 2 - word2vec (skip-gram 위주) (0) | 2021.08.01 |
| 중요!! 한국어 NLP 오픈소스 KLUE (1) | 2021.07.21 |
| 순환 신경망 RNN 1 (0) | 2021.07.05 |
| Customer2vec, Client2vec, item2vec, prod2vec (0) | 2021.06.10 |