2021. 8. 1. 13:49ㆍalgorithm/Deep Learning

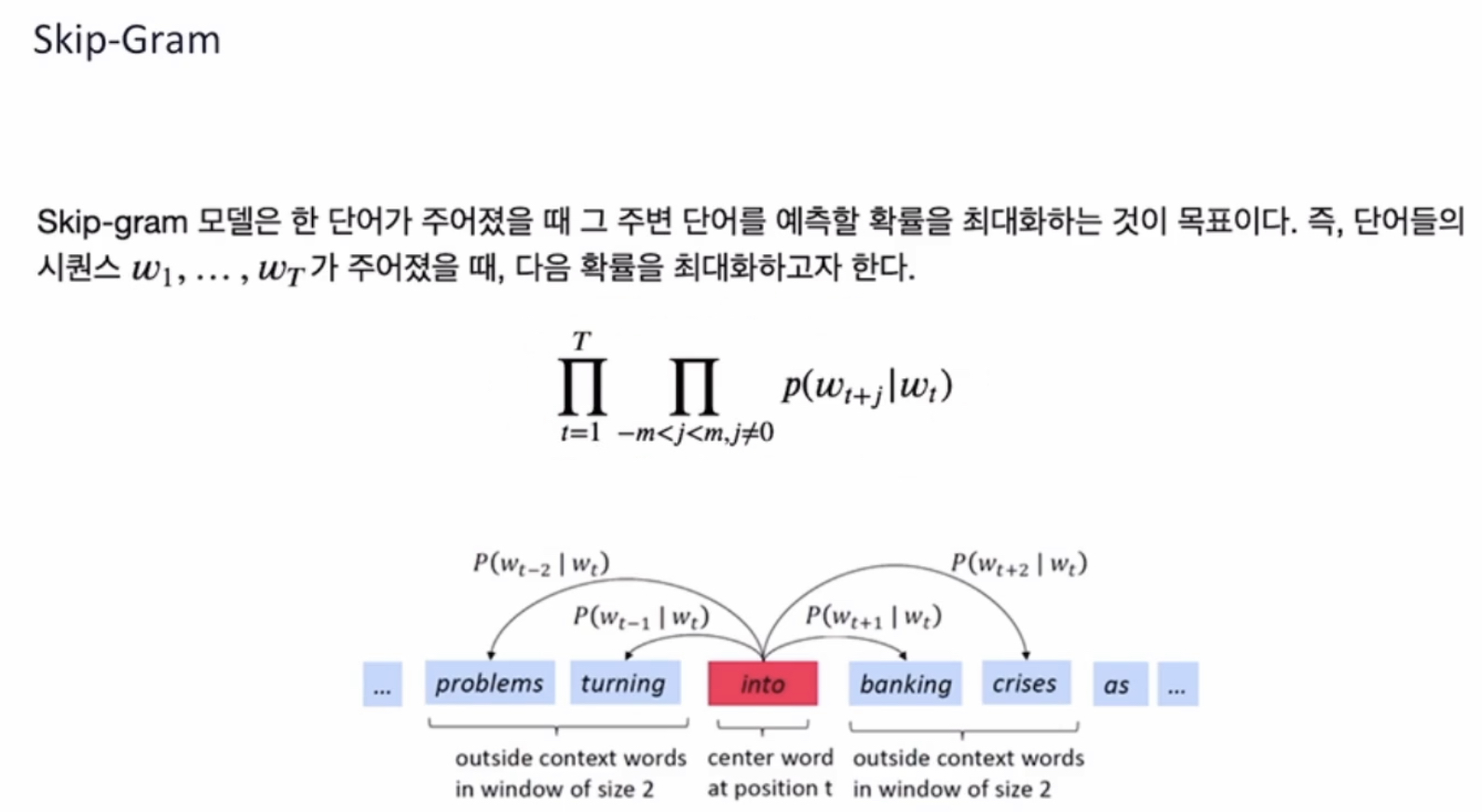
w = 타겟단어
c = context 단어(주변 단어)

목표 는 단어 w를 임베딩 하는 것
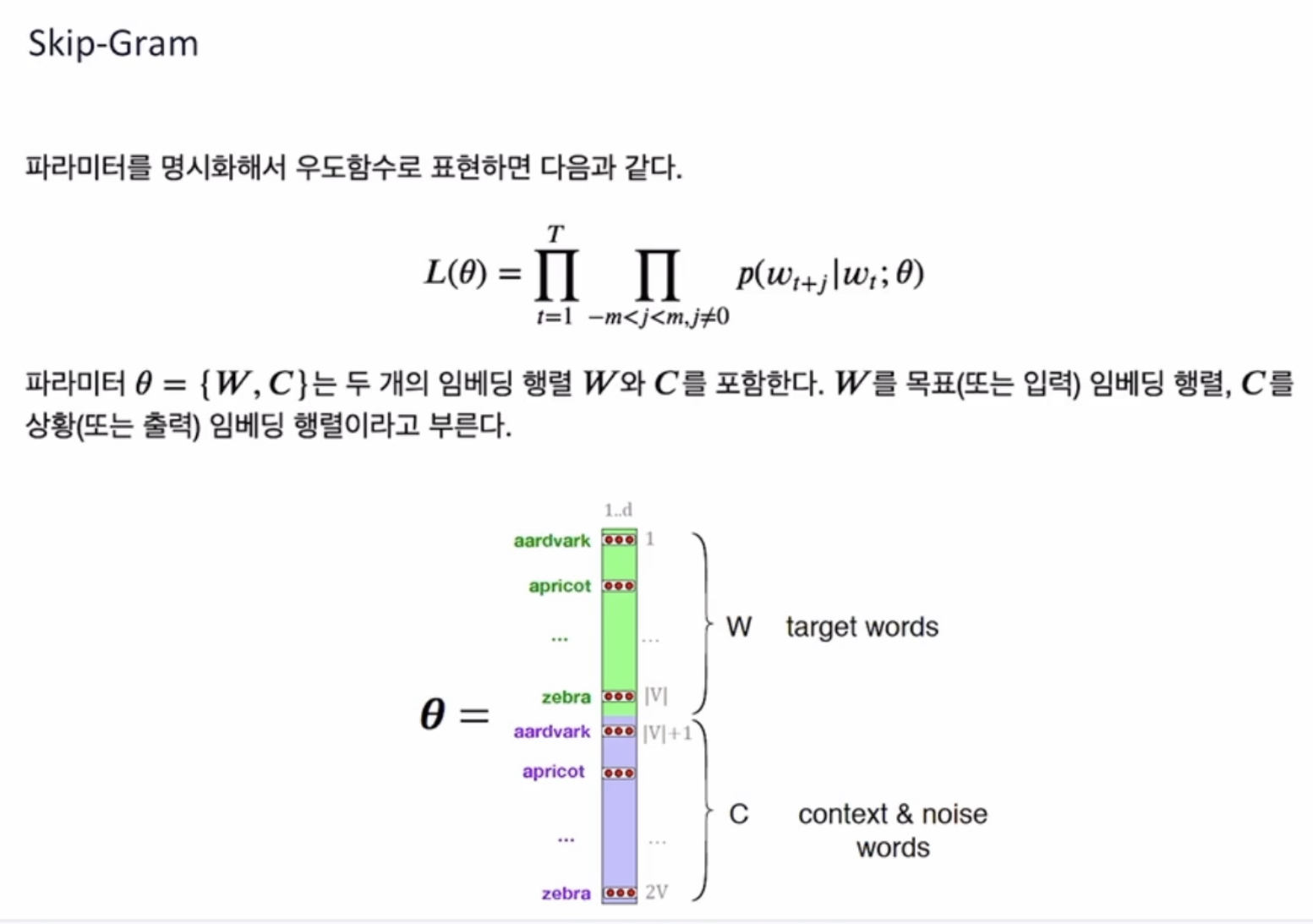
= softmax regression 하는 Vw
= 이게 주요 학습 대상.
~ 주변 단어의 벡터 Uc 는 softmax regression 잘 만들기 위한 부가적인 파라미터 (weight니까)

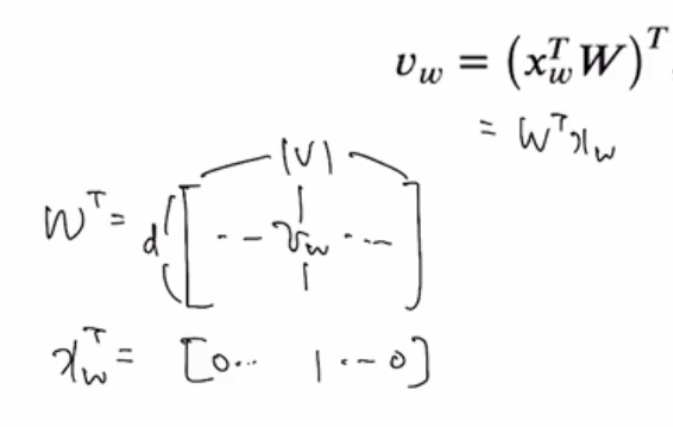
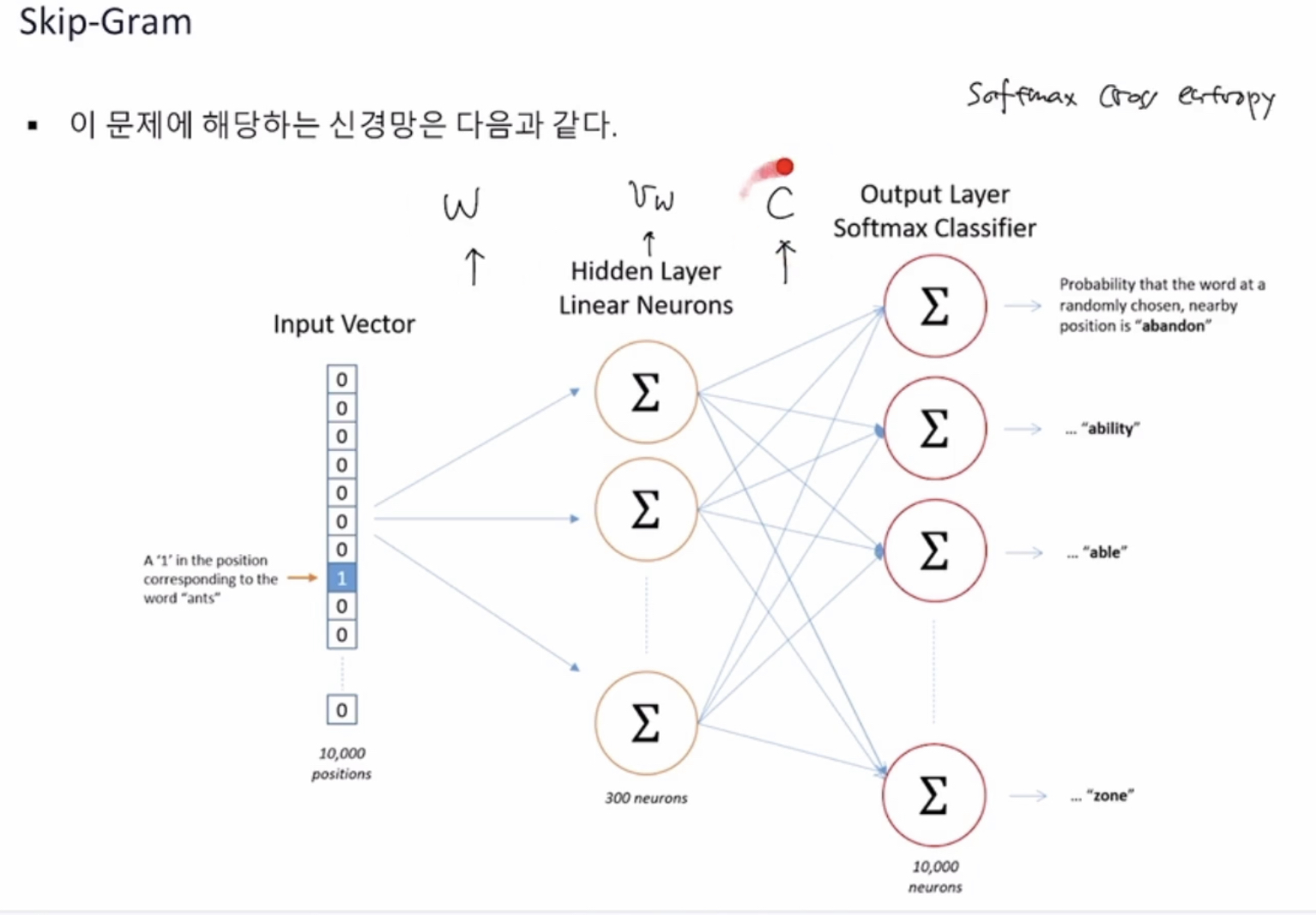
Input = 하나의 값만 1인 어떤 한 단어의 벡터
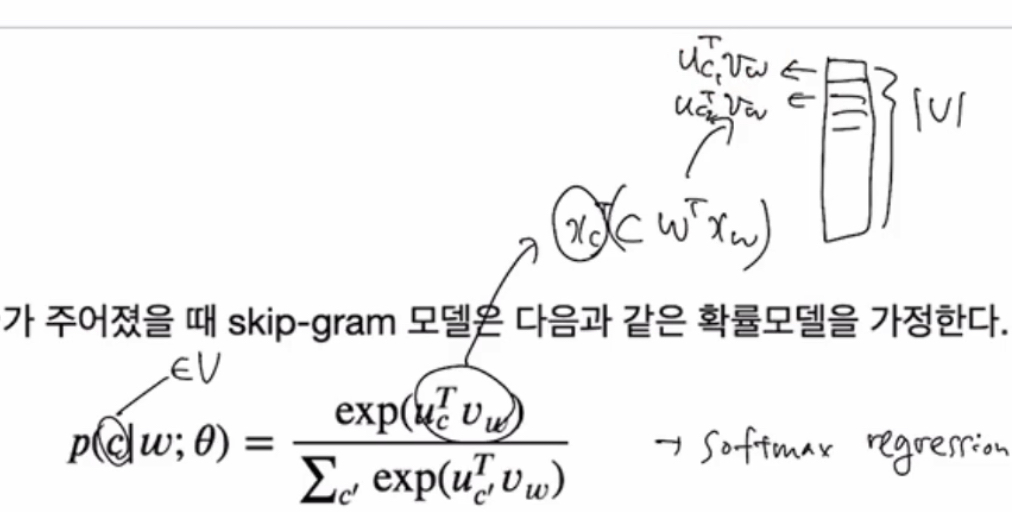
주변 단어들의 확률을 계산
Loss function을 softmax cross entropy 문제로 풀어내기 위해
Vw 를 히든 레이어로 사용하여,
가중치 W와 C를 업데이트 하는 과정

원래 스킵그램 모델은 multi-class classification 문제인데
NC estimation 으로 단순화

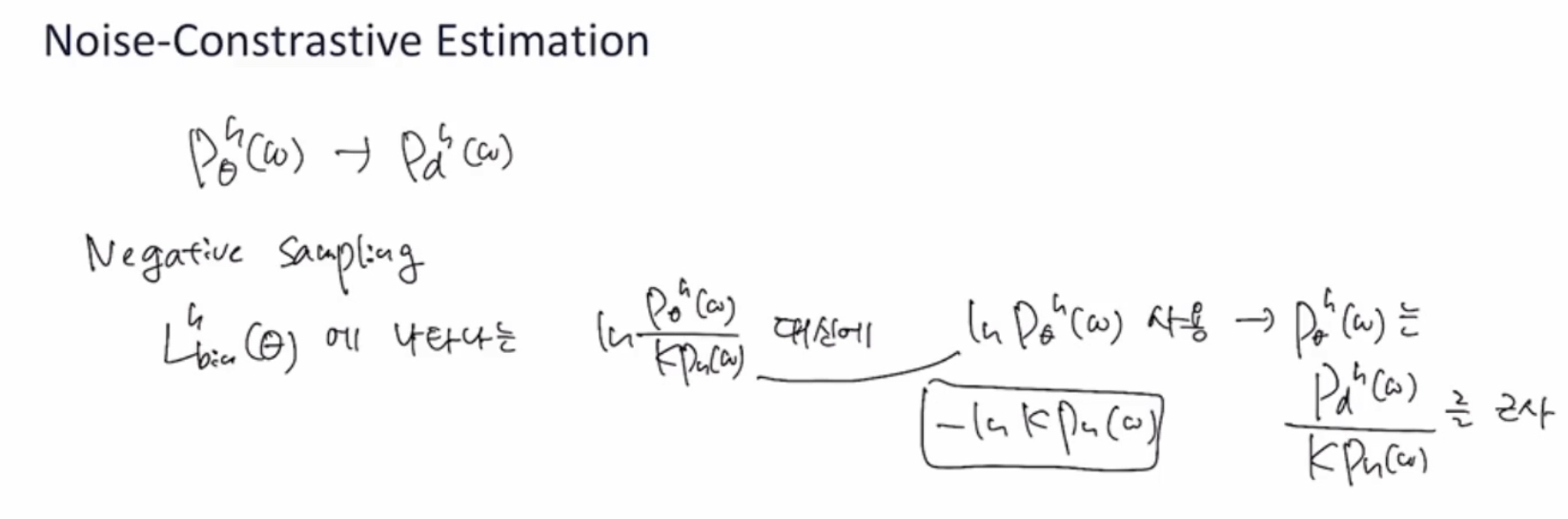
NCE의 핵심아이디어
1. 고차원 multi-class classification 문제를 binary classification 문제로 전환하게 되면 근사해를 구하게 된다
2. P_d of context h ( 다음단어w) 분모를 파라미터화 하여 데이터로부터 이 파라미터를 학습
1-1 ) 두가지 분포를 가정
- P_d of context h ( 다음단어w) : context h가 주어졌을 때 다음에 나오는 단어 w의 확률 분포
~ 모델링 목표는 이 확률분포를 가장 잘 나타내는 모델 만드는 것
-> 1개의 단어 샘플을 추출하여 ‘positive set’ 만듦
- 상관없는 단어일 확률 분포
-> 컨텍스트와 상관없는 확률에서 k개 샘플 만들어서 ‘negative set’ 만듦
- 어떤 단어가 positive set 에서 나왔는지(만약 그렇다면 t=1), negative set 에서 나왔는지(만약 그렇다면 t=0) “이진분류” 문제가 됨
log-likelihood Loss fuction

- 어떤 단어가 positive set 에서 나왔는지, negative set 에서 나왔는지에 대한 확률분포는 시그모이드 함수 형태
-> 앞에 마이너스를 곱해서 만든 negative-likelihood
= 우리가 최소화시켜야할 loss fuction
= 이 negative-likelihood는 logit fuction
~ 베이즈 정리를 통해 유도할 수 있음
- 분모를 사라지게 하기 위해서 exp(C_h) <= 데이터를 통해서 학습
결론적으로, word2vec에서는 w와 h 두 개 벡터의 dot product를 사용
k = positive label 하나당 negative label 몇 개 샘플링할 것인지 (하이퍼 파라미터)
P_h (w) = 하나의 단어가 주어져있을 때 단어가 noise ? negative 에서 나왔을 확률
NCE 증명의 핵심
1 다중분류에서 이중분류라는 더 쉬운 문제로 변환. 최종목표를 조금 희생하더라도, 풀기 더 쉽게 바꾼 것
2 negative sampling
- Loss fuction에 나타나는 logit 부분을 더 단순화 시키기 위함
- 분자에 나타나는 확률만 남겨서 근사시킴
원래 의도한 확률분포를 푸는게 아니라(그대로 근사시키는 게 아니라), 다른 loss fuction 사용 하는 것
- 정확하게 풀기보다, reasonably 비슷하게 푼다

즉 하나의 positive sample에 대해서 왼쪽항처럼
k개의 negative sample에 대해서 오른쪽항처럼
계산하는 loss fuction을 사용
- 원래의 multiclass위한 softmax cross entrophy가 아니라 binary 문제 위한 entrophy loss fuction으로 변환 한 셈

Word2vec 학습데이터 생성
- 하나의 positive sample 에 대해서 여러 개k개의 negative sample 생성
positive sample = t 타겟단어 + c 주변단어, context
negative sample = t 타겟단어 + c t와 상관없는/컨텍스트와 상관없는 단어들

'algorithm > Deep Learning' 카테고리의 다른 글
| PyTorch M1 에서 GPU 가속 사용하기 (1) | 2022.05.22 |
|---|---|
| NLP 6 - NLP 와 딥모델 (0) | 2021.09.05 |
| NLP 4 - 단어 임베딩 (0) | 2021.08.01 |
| 중요!! 한국어 NLP 오픈소스 KLUE (1) | 2021.07.21 |
| 순환 신경망 RNN 1 (0) | 2021.07.05 |